
https://arxiv.org/abs/2405.18929
https://github.com/takahashihiroshi/puae?tab=readme-ov-file
Introduction
通常、異常検知は正常のデータはほぼ無限に存在するが、異常なデータは学習時に与えられない。それで異常を検出するタスク。
実現の方法の1つとして、オートエンコーダーベースの手法では、学習データに関しては復元できるように学習させる。そして、異常データはオートエンコーダーに学習させていないので、復元したとき損失が非常に大きくなる。これをもって異常と判断する。
- 教師なしの異常検知では、「正常」と「ラベルなし(ほぼ正常)」のデータで学習する。
- 半教師なしの異常検知(contaminated unlabeled dataを使う)では、「異常」と「ラベルなし(ほぼ正常)」が与えられる。
- これらってPU Learningの問題設定と似ている。
だが通常のPU Leanringでは、以下の図のように、異常検知では決定境界を下手にひくと、その裏にある星の部分の異常も検出してくれない。
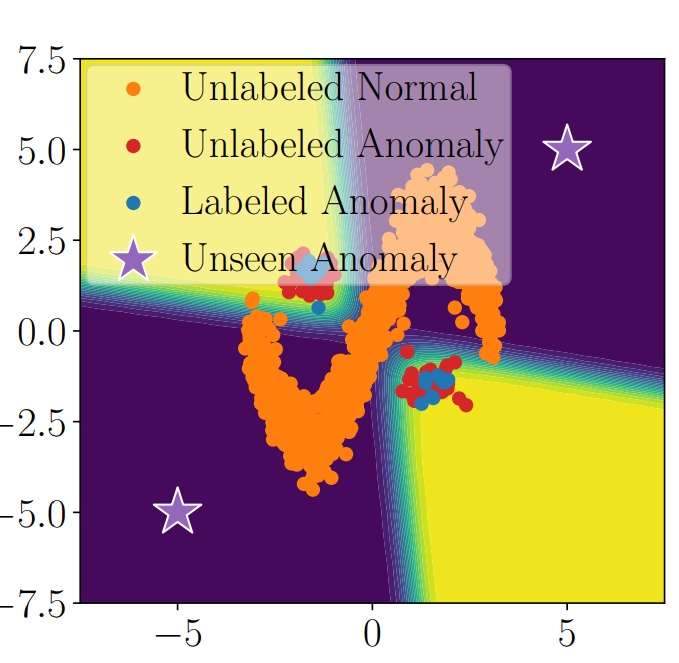
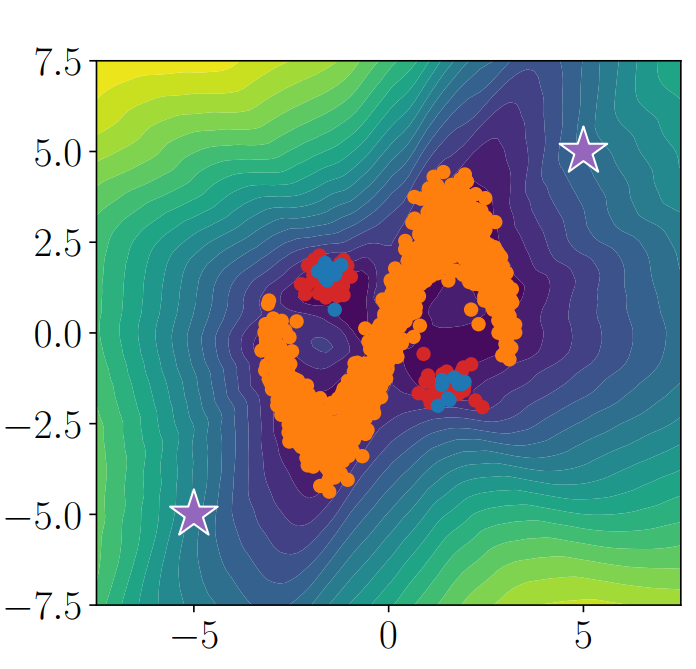
一方、Auto Encoderでは以下のように、正常=オレンジだけ与えられて学習をしても遠くだけを異常として扱うが、正常データの近くの異常例も、正常だと判断してしまう。
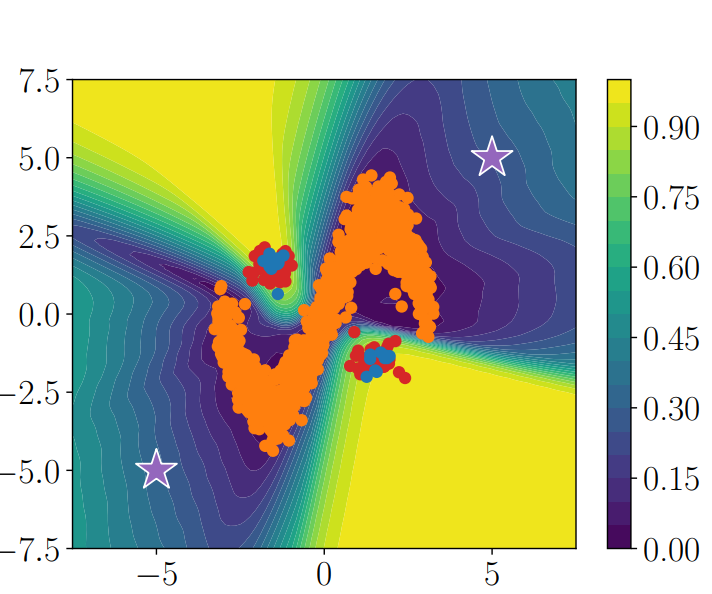
この手法は、AutoEncoderとPU Learningの両方のメリットを組み合わせて、以下のように
実現できている。
Preliminary
Auto Encoderでは、以下のように訓練データについて、復元したときの損失をできるだけ最小化させる。
これが、異常検知の時に使われる損失となる。
Auto-encoding binary Classifier(ABC)
先行研究として、異常検知の問題をUnsupervised LearningからSupervised Learningに拡充できる手法がある。
少量の異常データ(N)と、大量のほぼ正常のデータ(U)が与えられる問題設定を考える。
回帰モデルよりも、分類モデルのほうが訓練しやすい。
は再構成誤差について、以下のように異常検知の確率に意味づける。
なら正常で、が小さくなるほど確率が1に近づく。
なら異常で、が大きくなるほど確率が1に近づく。
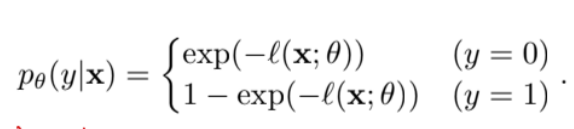
これを用いてCross Entropy Lossで訓練すると、以下のような目的関数になる。
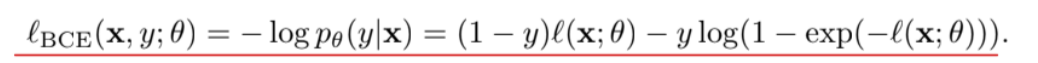
- 前の項は正常データに対しては、再構成誤差の最小化を目指す。
- 後ろの項は以上データに対して、与えられた異常データを用いれば、再構成後の最大化を目指せる。
しかし、この先行研究では、Normalだと思っているデータに多少Noisyなものが混入してしまうことがあるが、そのフレームワークで改善を施したのがこの研究である。
Proposed Method
ここで、PUというかNU Learningを用いて、与えられているほぼ正常(少しだけ異常あるかも)のデータをUnlabeledデータとして扱って、uPU, nnPUの式変形を用いて解く。
Class Priorをとする。
📄![]() 2015-ICML-[uPU] Convex Formulation for Learning from Positive and Unlabeled Data のように式変形をすると、以下のようになる。
2015-ICML-[uPU] Convex Formulation for Learning from Positive and Unlabeled Data のように式変形をすると、以下のようになる。
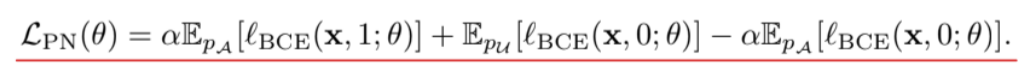
そして、いつも通り深層学習において、📄![]() 2017-NIPS-[nnPU] Positive-Unlabeled Learning with Non-Negative Risk Estimator のようにClippingやGradient Ascendを施すとよい。
2017-NIPS-[nnPU] Positive-Unlabeled Learning with Non-Negative Risk Estimator のようにClippingやGradient Ascendを施すとよい。
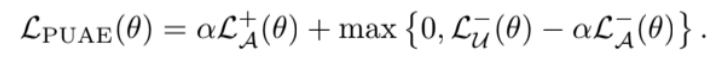
他のSOTAの異常検知手法への応用
Auto Encoderは過学習すると、学習データとピッタリのものだけ再構成できて、それ以外のものは再構成できないようになってしまう。
DAEという手法は、ランダムなガウシアンノイズを加えても、再構成できるような以下の再構成損失を考える。
これは学習データに少しでもノイズを加えてもうまくいくと行くようにしてしまうが、正常のすぐに異常があるかもしれない異常検知のタスクだと問題が起きてしまう。
DeepSVDDでは、Auto Encoderの内部の特徴がある任意の0ではない定数ベクトルに近づくようにする。0になると、Auto Encoderの明示的な望ましくない解として、パラメタが全部0になるような学習をしてしまうが、それを避けたい。
これらの方法でも、同じようにPUAEを用いることで、同じようにPUのフレームワークで改善される。
Experiments
Class Priorについて
Class Priorについては最初から与える。というのもClass Priorに該当するような値を大きくすると、どんどんうまくいってしまう。
なので、理論的にはまだ詰める余地はありそう。
Resamplingについて
Resamplingという、Minibatch内のPとUの数を同じにするという手法があるが、今回はAuto Encoderなので、ただ単に与えられたデータの形を捉えればよいので、PとUとあまり関係がない。